CI-1322
Autómatas y compiladores
Tarea #4
Clase
Token
Realizado por
:
Sharon Amador Vargas A10218 Roberto Hernández Montoya A11727
Tabla de Contenidos
Introducción
Mediante
la realización del presente trabajo se trata de ahondar aún más en el proceso del análisis sintáctico
que hace el compilador para reconocer los tokens del programa fuente, por medio
del ejemplo de una calculadora que a diferencia de la de la tarea #2 admite
números de más de un dígito, enteros y punto flotante. En esta tarea
utilizaremos el tokenizador yylex para mandarle carácter a carácter los tokens
que necesita para pasar a posfijo la expresión recibida y reconocer así lo que
sería análogo a los lexemas que el compilador encuentra y revisa, en sí en esta
tarea se mostrará una forma alternativa de resolver el problema de la
calculadora de la tarea #2 por medio de la clase token.
Descripción del
problema
Problema
Modificar el programa de la segunda tarea
para que use la clase Token usando la
implementación de la clase Token que se recibió en clase. También se debe cambiar el programa CLC.cpp para que ya no use el campo Calcualdora::_infijo, por lo que debe
eliminarse de la clase Calculadora. Además,
note que el campo Calculadora::preAnalisis
es de tipo "Token" y no un
"char" como en el
programa original.
Solución
La
solución propuesta se logró mediante la sustitución de las operaciones que
utilizaban _infijo, por operaciones realizadas mediante el extractor yylex,
guardando, y guardando la expresión obtenida en posfijo en un arreglo de
objetos de la clase Token. Se sustituyó en cada paso de las transformaciones de
la expresión, por las nuevas instrucciones utilizando la clase token, pero al
ver el código fuente se observa que se definió una constante denominada
cambios, que lo que hace es que si está definida, el programa trabaja con la
clase token y evalúa las expresiones, y si esta no se define, trabaja con la
antigua clase calculadora de la tarea numero dos.
Requerimientos
§
Conocer el
funcionamiento de la clase token.
§
Conocer el
funcionamiento de la clase Calculadora de la tarea #2
Especificación del programa
El
programa de la tarea # 2 era una calculadora que tomaba las expresiones
insertadas, las convertía a de infijo a posfijo e imprimía el resultado de la
evaluación en posfijo de la misma.
Al
modificar el programa se agrega la clase calculadora y se define una constante
denominada cambios que sirve para seleccionar el funcionamiento de la calculadora,
si no está definida la calculadora funciona haciendo uso de la clase
calculadora de la tarea #2, si lo está, trabaja haciendo uso del extractor
yylex para extraer la expresión insertada e ir leyéndola token por token
definiendo que tipo de token es cada uno y si existe un error o no.
Implementación
Clases:
Clase Token:
Esta clase
es un envoltorio que sirve para entregarle a yylex(), letra por letra, cada uno
de los caracteres que necesita para encontrar los tokens y lexemas que el
compilador procesa.
- Esta es
una clase abstracta. Los extractores son derivados de esta clase y redefinen el
método Saque() que se encarga de obtener el siguiente carácter a retornar.
- En los
campos de la clase derivada se puede almacenar los datos que permiten mantener
el estado actual de proceso, para evitar usar en yylex() variables estáticas o
globales.
- Jerarquía
para Extractor yylex:
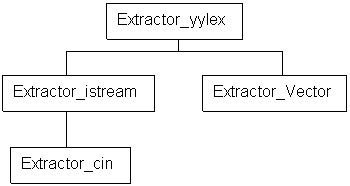
Clase
Astring:
Implementa algunas de las operaciones principales
para la clase "Astring" de hileras.
Compilador Usado
Visual C++ 6.0 Microsoft Compiler.
Cómo compilar el programa
Se proveen cinco archivos necesarios para la
compilación del programa: Tarea3.cpp, Astring.cpp y Astring.h, Token.h,
Token.cpp
Para compilar el programa simplemente se debe crear
un nuevo proyecto de consola en Visual C++ y luego agregar al proyecto los tres
archivos proveídos. Por último se compila el archivo Tarea3.cpp y se construye
el ejecutable para ver así el producto final.
Datos de prueba del programa
Los datos de prueba usados fueron las expresiones
- (333 *
87)
- ((2 +
4)*( 6 + 8))
- ((((2.53254
+ 44325432)* 643215) / 843243))
Formato de
prueba del programa:
Los
datos de prueba se insertaron en el main de la siguiente manera:
int main() {
char
str[200];
Calculadora
C;
cout << endl
<< endl;
strcpy(str, "((2 + 4)*( 6 +
8))");
cout<<"La
expresion en infijo es: "<<str<<endl;
C =
str;
Calculadora
C2;
cout
<< endl << endl;
strcpy(str,
"(333 * 87)");
cout<<"La
expresion en infijo es: "<<str<<endl;
C2 =
str;
Calculadora
C3;
cout << endl
<< endl;
strcpy(str, "((((2.53254 + 44325432)*
643215) / 843243))");
cout<<"La
expresion en infijo es: "<<str<<endl;
C3 =
str;
return 0;
} // main()
Salida del programa:

Código Fuente
Clases:
/
Token.h (c) adolfo@di-mare.com
/* resultado
Ejemplo de una analizador sint ctico
yylex(), implementado a mano
para la gram tica de la calculadora.
En la pr ctica es necesario
reprogramar yylex() para que reconozca un
conjunto de tokens y
lexemas diferente, pero la estructura
Token+Extractor+yylex() puede
ustilizarse en ese contexto diferente.
*/
#ifndef Token_h
#define Token_h
#include <iostream.h>
#include <iomanip.h>
#include <cctype>
#include
"Astring.h"
#if
defined(__BORLANDC__) // Compilando con
Borland C++
#include
<bool.h> // Define bool para
BC++ v3.1 o inferior
#endif
class
Extractor_yylex; // produce letras
para yylex()
int
yylex( Astring & lexema, char &estado, Extractor_yylex &extractor
);
// token = yylex(lexema, ch,
extractor);
// retorna: Un n£mero que representa el token, de
Token::Tipo
// lexema: atributo del token
// estado: recuerda el £ltimo valor obtenido de
"extractor"
// extractor: produce el siguiente
caracter a leer
void double_long( const char
*s, double &d, long& i );
class
Token {
/* Permite usar la pareja <Token, Lexema>
que retorna el analizador
l‚xico de un compilador [usualmente
yylex()].
*/
public:
enum Tipo {
OP_SUM = 321, // podr¡a ser otro, mientras no
"choque"
OP_MUL, // con otros valores para tokens
NUM,
P_ABRE,
P_CIERRA, ERROR
= 666, FIN = 999
};
const Astring& lexema() const { return
_lexema; }
int
token () { return _tipo;}
const char* Nombre() const { return Nombre(_tipo); }
static const char* Nombre(int);
void setTipo(int t){this->_tipo = (Tipo)t;}
void
setLexema(Astring l){this->_lexema = l;}
private:
Tipo
_tipo; // Token::Tipo
Astring _lexema;
};
// Token
inline
const char* Token::Nombre(int tipo) {
// Retorna el nombre del token
if
(tipo == Token::OP_SUM) return
"OP_SUM";
else if (tipo == Token::OP_MUL) return "OP_MUL";
else if (tipo == Token::NUM) return "NUM";
else if (tipo == Token::P_ABRE) return "P_ABRE";
else if (tipo == Token::P_CIERRA) return "P_CIERRA";
else if (tipo == Token::FIN) return "FIN";
else return
"ERROR";
// no pude lograr usar un switch() con BC++
v3.1
} // Token::Nombre()
class Extractor_yylex {
/* resultado
Esta clase es un envoltorio que sirve para
entregarle a yylex(),
letra por letra, cada uno de los caracteres
que necesita para
encontrar los tokens y lexemas que el
compilador procesa.
- Esta es una clase abstracta. Los
extractores son derivados de esta
clase y redefinen el m‚todo Saque() que
se encarga de obtener el
siguiente caracter a retornar.
- En los campos de la clase derivada se
puede almacenar los datos
que permiten maneter el estado actual de
proceso, para evitar usar
en yylex() variables est ticas o
globales.
- Jerarqu¡a para Extractor_yylex:
+-----------------+
| Extractor_yylex |
+-----------------+
|-------------------------+
| |
+-------------------+ +------------------+
| Extractor_istream | | Extractor_Vector |
+-------------------+ +------------------+
|
|
+----------------+
| Extractor_cin |
+----------------+
*/
public:
virtual char Saque() = 0; // retorna el
siguiente caracter
}; // Extractor_yylex
class Extractor_istream :
public Extractor_yylex {
public:
Extractor_istream(istream &CIN)
:_CIN(CIN) {}
virtual
char Saque() {
//
Obtiene el siguiente caracter del flujo de entrada.
return _CIN.get(); // jala una sola letra
/*
nota
Al principio esta funci¢n estaba
implementada as¡:
_CIN >> ch;
Desafortunadamente esta forma de
lectura hace que >>() se
trague los espacios en blanco y el
fin de l¡nea '\n', lo que
impide que la l¢gica de yylex()
funcione correctamente. La
soluci¢n fue usar istream::get(),
que lee s¢lo un caracter.
*/
}
// Extractor_istream::Saque()
private:
istream &_CIN;
}; // Extractor_istream
class Extractor_cin : public
Extractor_istream {
/* resultado
Este extractor sirve para obtener de la
entrada est ndar "cin" las
letras que yylex() procesar , para
obtener a partir de ellas tokens.
- Para eso redefine el m‚todo Saque() de la
clase base.
- El que Saque() sea una funci¢n virtual
puede parecer poco
eficiente, pero hay que tomar en cuenta
que la mayor parte de los
programas son realtivamente peque¤os, y
la funci¢n Saque() es
invocada s¢lo una vez para procesar cada
una de las letras del
c¢digo fuente, lo que represanta unos
pocos miles de veces para la
mayor parte de los programas. El costo
del desperdicio en tiempo
de proceso causado por el uso de la
invocaci¢n al m‚todo virtual
Saque() es despreciable si se compara con
la ventaja que
representa delimitar claramente la
funcionalidad que correponde a
cada uno de los componentes del compilador.
- Saque() se ejecuta O(n) veces, n ==
cantidad de letras.
*/
public:
Extractor_cin() : Extractor_istream(cin) {}
};
// Extractor_cin
class
Extractor_Vector : public Extractor_yylex {
/* resultado
Este extractor sirve para obtener las
letras que yylex() procesar a
partir del contenido de un vector de
caracteres. El vector debe
contener una hilera C++ v lida, con el
caracter EOF '\0' marcando el
final de la hilera.
- Por eso redefine el m‚todo Saque() de la
clase base.
*/
public:
Extractor_Vector() : _vec(0), _end(0) { }
Extractor_Vector(const char* v) { _vec = v;
_end = v+strlen(v); }
virtual
char Saque() {
/*
retorna el siguiente caracter del vector.
- Este Saque() es
"inteligente" porque cuando se acaba el vector
retorna '\n' que es lo que yylex()
necesita para saber que
debe retornar Token::FIN.
*/
return (_vec == _end ? '\n' : *_vec++
);
} // Extractor_Vector::Saque()
Extractor_Vector & operator = (const
char *v)
{ _vec = v; _end = v+strlen(v); return
*this; }
private:
const char *_vec; // principio del vector
const char *_end; // uno m s all
del final del vector
}; // Extractor_Vector
#endif // Token_h
// EOF: Token.h
// Token.cpp (c)
adolfo@di-mare.com
#include
"Token.h"
int
yylex( Astring & lexema, char &estado, Extractor_yylex &extractor )
{
/* resultado
Retorna el siguiente token, junto con su
lexema.
- Invoca extractor.Saque() para obtener el
siguiente caracter a
procesar.
- Se brinca los espacios en blanco.
- "estado" contiene el estado de
lectura anterior, y generalmente se
obtiene de un llamado previo.
- Es usual inicializar "estado"
con un espacio en blanco ' '.
- Cuando el "extractor" retorna
'\n' (fin de la l¡nea), yylex()
indica que ha terminado de procesar la
entrada retornado
Token::FIN.
- El "extractor" debe retornar,
eventualmente, el '\n', o nunca se
obtendr Token::FIN.
- Para crear un nuevo "extractor"
es necesario derivar de la clase
Extractor_yylex e implementar el m‚todo
virtual Saque(), que es el
que retorna el siguiente caracter. Las
clases Extractor_Vector y
Extractor_cin sirven para que yylex()
trabaje leyendo las letras
de una hilera o de "cin" (la
hilera debe contener el caracter de
fin de l¡nea '\n' o yylex() se tragar¡a
toda la memoria).
*/
int
token;
char ch = estado; // "ch" es un nombre m s significativo
while (ch == ' ') { // se brinca los blancos
ch = extractor.Saque(); // jala una sola letra
}
if (ch == '\n') { // ya es hora de parar
lexema = "";
return Token::FIN;
}
else if (isdigit(ch)) {
lexema = "";
token = Token::NUM;
bool ya_punto = false; //
"true" despu‚s de ver el primer '.'
for (;;) { // ciclo para leer todos los
d¡gitos
if (isdigit(ch)) {
lexema += ch; // agrega el numerito
}
else if (ch=='.') {
if (ya_punto) { // es el
segundo punto
token = Token::ERROR;
break;
}
else {
ya_punto = true;
lexema += ch;
}
}
else if ((ch == ',') || (ch ==
'_')) {
// se brinca las comas
}
else {
break; // ya termin¢: quiebra
el ciclo y retorna
}
ch = extractor.Saque(); // obtiene el siguiente caracter
}
}
else { // no es d¡gito: averigua qu‚ es
lexema = ch;
switch (ch) {
case '(': { token = Token::P_ABRE; break; }
case ')': { token = Token::P_CIERRA; break; }
case '+': { token = Token::OP_SUM; break; }
case '-': { token = Token::OP_SUM; break; }
case '*': { token = Token::OP_MUL; break; }
case '/':
{ token = Token::OP_MUL; break;
}
case '%': { token = Token::OP_MUL; break; }
default:
token = Token::ERROR;
}
ch = extractor.Saque(); // obtiene el siguiente caracter
}
estado = ch; // Recuerda lo £ltimo leido para la
siguientes invocaci¢n
return token;
} // yylex()
void double_long(const char
*s, double &d, long& n) {
/* resultado
Toma la hilera "s" que contiene
un n£mero sin signo, posiblemente de
punto flotante, y retorna el valor num‚rico
que representa.
- El valor almacenado en "s" debe
tener la forma:
"######.ddddd", en donde
"#" y "d" son d¡gitos decimales.
*/
/* requiere
- La hilera "s" no puede contener
espacios ni el signo negativo '-'.
*/
static double dg[] = {
0.0, 1.0, 2.0, 3.0, 4.0,
5.0, 6.0, 7.0, 8.0, 9.0 };
unsigned i = 0; // ¡ndice en s[]
n = 0;
d = 0.0;
while (isdigit(s[i])) {
n = n * 10 + (
s[i] - '0' );
d = d * 10.0 + dg[ s[i] - '0' ];
++i;
}
double dec = 0.0;
double mul = 1.0;
if (s[i] == '.') { // s¡ tiene decimales
++i;
while (isdigit(s[i])) {
dec = dec * 10.0 + dg[ s[i] - '0'
];
mul = mul * 10.0;
++i;
}
d = d + dec/mul;
}
} // double_long()
// EOF: Token.cpp
// Calculadora.cpp (C) adolfo@di-mare.com
/* resultado
Eval£a expresiones aritm‚ticas simples en
que los
operandos son n£meros del 0 al 9.
*/
#if
defined(__BORLANDC__) // Compilando con
Borland C++
#include <bool.h> // Define bool para
#endif
#include
"Astring.h" // class
string
#include <iostream.h>
#include <cctype>
/*------------------------------------------------------------------------------------*/
#define
CAMBIOS 21 //define una constante para aplicar los
cambios al código
#define
LON 10 //Longitud
del arreglo para la expresión en posfijo
#ifdef CAMBIOS
#include "Token.h"
#else
typedef char
Token;
#endif
/*------------------------------------------------------------------------------------*/
//Plantilla
para la clase pila, NO fue modificada
template <class T>
class Pila {
public:
Pila() { _top = 0; }
void
Push(T d);
T
Pop();
T
top() { return _vec[_top]; }
private:
enum { Capacidad = 132 };
int
_top; // tope de la
pila
T
_vec[Capacidad]; // vector para la pila
}; // Pila
template <class T>
inline void Pila<T>::Push(T d) {
_vec[_top] = d;
_top++;
}
template <class T>
inline T Pila<T>::Pop() {
_top--;
return _vec[_top];
}
/*------------------------------------------------------------------------------------*/
class Calculadora {
public:
Calculadora(const char* exp=0);
void operator = (const char* exp);
long Evaluar();
// expr ==>
term r1
private: // r1
==> + term r1
void expr(); //
r1 ==> - term r1 | œ
void r1(); //
void term(); //
term ==> factor r2
void r2(); //
r2 ==> * factor r2 | œ
void factor(); //
r2 ==> / factor r2
void num(); //
// factor ==> ( expr ) | num
//
#ifndef CAMBIOS
void aparea(Token); //
num ==> 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
#else
void aparea(int); //recibe un int porque es el que identifica un
token
void imprimirPosfijo(); //para imprimir en pantalla la expresión
en posfijo
#endif
void Trabaje(const char*);
void error(const char * msg);
private:
Token
preAnalisis; // siguiente token
#ifndef
CAMBIOS //antes ocupaba estas variables
Astring _infijo; // hilera inicial
Astring _posfijo; // hilera resultado
size_t
_cursor; // posici¢n en _infijo
#else
//Estas
son las variables nuevas
Token _posfijo[LON]; //guarda el resultado
int pos;
//para manejar la posición en _posfijo
Extractor_Vector* extractor_str; //ocupa un extractor para yylex()
char estado; //guarda
el token anterior
Astring lexema; //para
el lexema que guarda yylex()
#endif
}; // Calculadora
Calculadora::Calculadora(const
char* exp){
//Constructor
#ifndef
CAMBIOS
_infijo
(exp);
Trabaje(exp);
#else
pos = 0;
for(int i=0; i<LON;i++){ //inicializa los tokens
_posfijo[i].setTipo(-1);
}
#endif
}
void
Calculadora::operator = (const char* exp){
#ifndef
CAMBIOS
_infijo = exp;
Trabaje(exp);
#else
extractor_str = new Extractor_Vector(exp); //inicializa el extractor
Trabaje(exp);
#endif
}
void
Calculadora::Trabaje(const char* exp) {
/* resultado
Traduce a notaci¢n posfija la exrpesi¢n
almancenada
en *this.
- Para evaluarla, hay que invocar a
Calculadora::Evaluar().
*/
/* requiere
- La expresi¢n almacenada no debe tener
errores de sintaxis.
*/
#ifndef
CAMBIOS
_posfijo = "";
if (_infijo == "") { // No se digit¢ ninguna expresi¢n
return;
}
_cursor = 0;
while (_infijo[_cursor] == ' ') { // ignora
blancos al inicio
_cursor++;
}
preAnalisis = _infijo[_cursor]; //
inicializa preAnalisis
#else
estado = ' '; //para la primera
llamada a yylex
int t = yylex(lexema,
estado,*(Extractor_yylex *)extractor_str);
preAnalisis.setTipo (t); //asigna
valores a preAnalisis
preAnalisis.setLexema(lexema);
#endif
//en cualquiera de los dos casos
hay que llamar a expr()
expr(); // reconocer la expresi¢n _infijo
this->imprimirPosfijo();
}
// Calculadora::Trabaje()
void
Calculadora::error(const char * msg) {
/* resultado
Graba en "cout" un mensaje de
error.
- Indica la posici¢n actual de proceso en
al hilera de entrada.
*/
#ifndef
CAMBIOS
cout << "ERROR(" <<
1+_cursor << ")";
if (msg != 0) { // +1 porque _cursor comienza en 0
if (msg[0] != 0) {
cout << ": "
<< msg;
}
}
cout << endl;
#endif
}
// Calculadora::error()
void
Calculadora::expr() {
// expr ==> term r1
term();
r1();
}
// Calculadora::expr()
void
Calculadora::r1() {
// r1 ==> + term r1
// r1 ==> - term r1
// r1 ==> œ
#ifndef CAMBIOS
if (preAnalisis == '+') { // r1 ==> + term r1
aparea('+');
term(); {{ _posfijo += '+'; }}
r1();
} else if (preAnalisis == '-') { //
r1 ==> - term r1
aparea('-');
term(); {{ _posfijo += '-'; }}
r1();
} else { } //
r1 ==> œ
#else
//yylex() le asigna OP_SUM tanto
a la suma como a la resta
//por lo que solo hay que hacer
una comparación
if(preAnalisis.token()==Token::OP_SUM){
Astring
lexTemp = preAnalisis.lexema(); //hay
que crear un Astring temporal
//para guardar el lexema
aparea(Token::OP_SUM);
term();
Token temp; //crea
un token temp porque preAnalisis fue cambiado
temp.setTipo(Token::OP_SUM); //le asigna un tipo y el lexema que venía
temp.setLexema(lexTemp);
_posfijo[pos]=
temp; //guarda
el token en _posfijo
pos++; //aumenta
el iterador
r1();
}
else{} // r1 ==> œ
#endif
}
// Calculadora::r1()
void
Calculadora::term() {
// term ==> factor r2
factor();
r2();
}
// Calculadora::term()
void
Calculadora::r2() {
// r2 ==> * factor r2
// r2 ==> / factor r2
// r2 ==> œ
#ifndef
CAMBIOS
if (preAnalisis == '*') { // r2 ==> * factor r2
aparea('*');
factor(); {{ _posfijo += '*'; }}
r2();
} else if (preAnalisis == '/') { //
r2 ==> / factor r2
aparea('/');
factor(); {{ _posfijo += '/'; }}
r2();
}
else { } //
r2 ==> œ
#else
//OP_MUL funciona para
multiplicacion y división por lo que solo se
//requiere una comparación
if(preAnalisis.token()==
Token::OP_MUL){
Astring lexTemp =
preAnalisis.lexema();
aparea(Token::OP_MUL);
factor();
Token temp;
temp.setTipo(Token::OP_MUL);
temp.setLexema(lexTemp);
_posfijo[pos]=
temp;
pos++;
r2();
}
else{};
#endif
}
// Calculadora::r2()
void
Calculadora::factor() {
// factor ==> ( expr )
// factor ==> num
#ifndef
CAMBIOS
if (preAnalisis == '(') { // factor ==> ( expr )
aparea('(');
expr();
aparea(')');
} else if (isdigit(preAnalisis)) { //
factor ==> num
num();
} else {
error("El factor no es d¡gito ni
'('");
}
#else
if (preAnalisis.token() == Token::P_ABRE) { //
factor ==> ( expr )
aparea((int)Token::P_ABRE);
expr();
aparea(Token::P_CIERRA);
} else if (preAnalisis.token() == Token::NUM)
{ //
factor ==> num
num();
} else {
error("El factor no es d¡gito ni
'('");
}
#endif
}
// Calculadora::factor()
void
Calculadora::num() {
// num ==> 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8
| 9
#ifndef
CAMBIOS
if (isdigit(preAnalisis)) {
{{ _posfijo += preAnalisis; }}
aparea(preAnalisis);
} else {
error("El token no es
d¡gito");
}
#else
if(preAnalisis.token()==Token::NUM){
_posfijo[pos]
= preAnalisis; //guarda
el token en _posfijo
pos++;
aparea(Token::NUM);
}else{
error("El
token no es d¡gito");
}
#endif
}
// Calculadora::num()
#ifndef
CAMBIOS
void
Calculadora::aparea(Token){
if (preAnalisis != ch) {
error("Token inesperado");
}
preAnalisis = _infijo[++_cursor];
while (_infijo[_cursor] == ' ') { // ignora
blancos
preAnalisis = _infijo[++_cursor];
}
}
#else
void
Calculadora::aparea(int ch) {
/* resultado
Consume el terminal, y avanza al siguiente
lexema.
- Si "ch" no coincide con el
valor de "preAnalisis"
emite un error.
*/
if(preAnalisis.token() != ch){
error("Token
inesperado");
}
int t = yylex(lexema,
estado,*(Extractor_yylex *)extractor_str);
//avanza al siguiente lexema
preAnalisis.setTipo (t);
preAnalisis.setLexema(lexema);
}
// Calculadora::aparea()
void
Calculadora::imprimirPosfijo(){
cout<<"\nLa expresion
en posfijo es: ";
int i=0;
while((i<LON)&&(_posfijo[i].token()!=-1)){
Astring lex =(_posfijo[i].lexema());
char * imp = lex.get_s();
cout<<imp<<" ";
i++;
}
cout<<endl<<endl;
}
#endif
long
Calculadora::Evaluar() {
/* resultado
Eval£a la expresi¢n contenida en
"*this".
*/
Pila<long> P; // pila usada para evaluar _posfijo
#ifndef CAMBIOS
size_t len = strlen(_posfijo);
if (len==0) {
return 0;
}
for (size_t i=0; i < len; ++i) { // recorre toda la expresi¢n
long op1, op2;
if (isdigit(_posfijo[i])) {
// si es un d¡gito lo mete en la pila
P.Push( _posfijo[i] - '0');
}
else if (_posfijo[i] == '+') { // Si es +, saca los operandos
op1 = P.Pop(); // de la pila y los suma
op2 = P.Pop();
P.Push(op2 + op1); // mete el
resultado intermedio en la pila
} else if (_posfijo[i] == '-')
{ // Si es - resta
op1 = P.Pop();
op2 = P.Pop();
P.Push(op2 - op1); // lo mete en
la pila
} else if (_posfijo[i] ==
'*') {
op1 = P.Pop();
op2 = P.Pop();
P.Push(op2 * op1);
} else if (_posfijo[i] == '/') {
op1 = P.Pop();
op2 = P.Pop();
if (op1 != 0) { // para no dividir entre 0
P.Push(op2 / op1);
} else {
P.Push(0);
error("Divisi¢n por
cero");
}
}
}
#endif
return P.Pop();
}
// Calculadora::Evaluar()
Programa de
prueba:
int
main() {
char str[200];
Calculadora C;
//
long V;
cout << endl << endl;
strcpy(str, "((2 + 4)*( 6 +
8))");
cout<<"La
expresion en infijo es: "<<str<<endl;
C = str;
Calculadora C2;
cout << endl << endl;
strcpy(str, "(333 * 87)");
cout<<"La expresion en
infijo es: "<<str<<endl;
C2 = str;
Calculadora C3;
cout << endl <<
endl;
strcpy(str, "((((2.53254 + 44325432)*
643215) / 843243))");
cout<<"La
expresion en infijo es: "<<str<<endl;
C3 = str;
*/ return 0;
} // main()